
다음과 같은 스프레드시트 프로그램으로 작업 뛰어나다 다양한 공식과 방정식을 사용하여 무한한 가능성을 제공합니다. 사용 가능한 기능은 학업 및 전문 문서에 필요한 거의 모든 요구 사항을 다룹니다. 오늘 우리는 특히 다음 질문에 초점을 맞출 것입니다. 엑셀 표준편차 계산법.
표준 편차는 무엇입니까?
이 개념은 통계 계산을 수행할 때 매우 중요합니다. 표준편차 또는 표준편차의 이름으로도 알려져 있으며 소문자 그리스 문자 시그마(σ) 또는 라틴 문자 "s"의 소문자로 약식으로 표현됩니다. 또한 일반적으로 영어 약어 SD로 표시됩니다. 표준 편차.
이 미터는 변동을 정량화하는 데 사용됩니다. 숫자 데이터 세트 또는 샘플의 분산. 표준 편차는 항상 XNUMX보다 크거나 같습니다. 편차 정도가 낮으면(XNUMX에 가까움) 대부분의 데이터가 평균에 가깝게 집중되어 있음을 의미합니다. 반면에 편차가 크다는 것은 데이터가 더 분산되어 있고 더 넓은 범위의 값을 포함한다는 것을 나타냅니다.
표준 편차의 계산은 다음을 가질 수 있습니다. 매우 실용적인 응용 프로그램 특정 통계 연구에서. 가장 큰 유용성은 변수의 평균 분산 정도, 즉 그룹의 다른 값이 평균 값에서 얼마나 멀리 떨어져 있는지 알 수 있다는 것입니다.
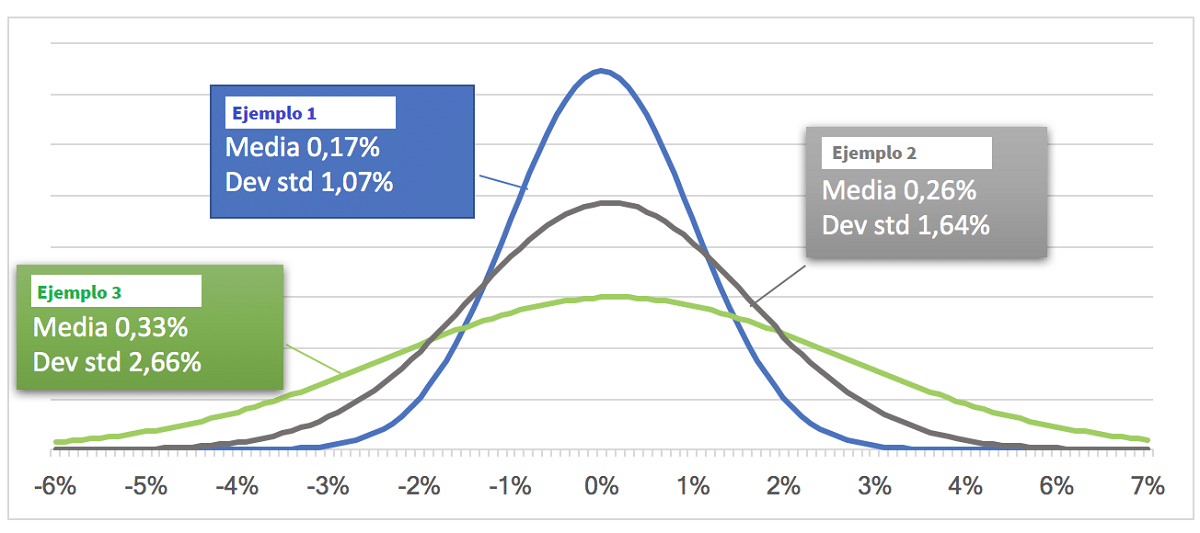
평균과 표준 편차 간의 관계에 대한 세 가지 다른 예
El 그래픽 이 라인의 은 표준 편차의 세 가지 다른 예를 보여줍니다: 높음, 중간 및 낮음, 각각은 특정 평균 값과 관련되어 있습니다.
그것을 설명하는 매우 조잡한 방법은 다음 예입니다. 두 가지 다른 경우:
- 사례 1: 38세, 40세, 42세 형제로 구성된 그룹을 상상해 봅시다. 평균은 40이지만 표준편차가 작다, 모든 값이 그것에 가깝기 때문에 평균 값에서 불과 XNUMX년 차이가 나는 값입니다.
- 카소 2이제 형제의 나이가 25세, 40세, 55세라고 가정해 보겠습니다. 평균은 여전히 40이지만 스프레드가 더 큽니다. 즉, 표준편차가 더 크다, 평균값에서 XNUMX년 떨어진 값으로.
데이터 계열 분포의 평균과 표준 편차를 알면 특정 값에 대해 더 높거나 낮은 결과를 얻을 확률을 계산할 수 있습니다. 많은 사람들에게 추상적으로 보일 수 있지만 이 계산은 예를 들어 재무 모델링에서 매우 중요한 의미를 갖습니다.
그러나 수학적 미로에서 길을 잃는 위험을 무릅쓰는 대신 이 게시물의 주요 질문이자 핵심 주제인 Excel에서 표준 편차를 계산하는 방법에 집중해 보겠습니다.
Excel에서 표준 편차를 계산하는 방법
Excel 워크시트에서 이 수학적 계산을 실행하는 것은 매우 간단하고 매우 빠릅니다. 이를 달성하려면 다음 단계를 따라야 합니다.
- 우선 분명히 있을 것이다. Microsoft Excel을 입력하고 스프레드시트에 액세스 여기에는 표준 편차를 얻으려는 데이터가 포함됩니다.
- 다음으로 사용하려는 값을 소개해야 합니다. 이를 위해 열을 선택하고 각 셀의 각 데이터 값을 씁니다..
- 선택한 열에 모든 데이터를 입력했으면 다음 단계는 빈 셀. 표준 편차 값이 나타날 결과에 대해 선택한 셀입니다.
- 바에서 위로 우리는 공식을 소개합니다 우리가 선택한 빈 셀에 대한 표준 편차. 공식은 다음과 같습니다.
= DEVEST.P (XX:XX)
STDEV는 "표준편차"의 약자이고 P는 모집단, 즉 "표본"을 나타냅니다. 괄호 안에 있는 값은 해당 샘플의 다른 값을 포함하는 선택된 셀에 해당합니다.
- 다음 단계는 값 범위 할당 Excel에서 계산을 수행할 항목입니다. 괄호 사이에 정확하게 입력해야 합니다. 거기에 각 셀의 문자와 번호를 써야 합니다. 예를 들어 셀이 A2에서 A20까지 상관관계가 있는 경우 콜론(:)으로 구분하여 첫 번째와 마지막을 간단히 씁니다. 이 예를 따르면 = STDEV.P(A2: A20)와 같습니다.
- 마지막 단계는 키를 누르는 것입니다. "시작하다" Excel에서 수식을 적용하고 처음에 선택한 셀에 결과를 표시합니다.
Microsoft Excel의 STDE 함수는 다음 수식을 사용합니다.
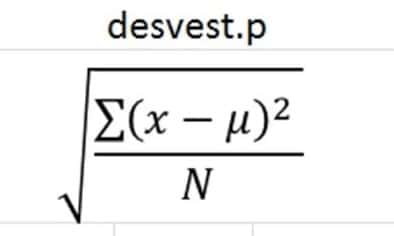
여기서 "x"는 평균 샘플 평균 값(value1, value2, ...)을 취하고 "n"은 크기를 나타냅니다.
Excel을 사용한 기타 통계 계산
Excel에서 표준 편차를 계산하는 방법을 아는 것 외에도 워크시트에서 데이터를 구성할 때 다른 수식에 의존해야 할 가능성이 매우 높습니다. 가장 일반적인 것은 다음과 같은 값을 계산할 수 있게 해주는 것입니다. 평균, 중앙값, 모드 및 분산.
미디어
모두가 알고 있듯이 미디어 (산술 평균이라고도 함)은 다른 숫자 값을 더하고 시리즈의 총 요소 수로 나눈 결과입니다. 평균을 얻기 위해 시스템은 Excel에서 표준 편차를 계산하는 데 사용되는 시스템과 실질적으로 동일합니다. 유일한 차이점은 적용되는 공식이며 이 경우에는 다음과 같습니다. = 평균(값X: 값Y).
중앙값
La 중앙값 종종 평균과 혼동되는 일련의 숫자는 계열의 평균 위치에 있는 값입니다. 평균과 일치할 필요는 없습니다. Excel에서 계산에 적용되는 수식은 다음과 같습니다. = 중앙값(값X: 값Y).
유행
La 유행 숫자 집합 중 가장 많이 반복되는 값입니다. 또한 반드시 평균이나 중앙값과 일치해야 하는 것도 아닙니다. Excel에서 계산하는 공식은 다음과 같습니다. = 모드(값X: 값Y).
변화
이 개념은 이전 개념보다 다소 복잡합니다. NS 바리 안자 평균 및 표준 편차와 밀접하게 관련되어 있습니다. 값 집합이 평균에서 멀어지는 "거리"만 참조하여 숫자 값 집합의 분산을 측정하는 또 다른 방법입니다. 공식: = VAR(값X:값Y).